理论
#简介
虚拟线程具有和 Go 语言的 goroutines 和 Erlang 语言的进程类似的实现方式,它们是用户模式(user-mode)线程的一种形式。
在过去 Java 中常常使用线程池来进行平台线程的共享以提高对计算机硬件的使用率,但在这种异步风格中,请求的每个阶段可能在不同的线程上执行,每个线程以交错的方式运行属于不同请求的阶段,与 Java 平台的设计不协调从而导致:
- 堆栈跟踪不提供可用的上下文
- 调试器不能单步执行请求处理逻辑
- 分析器不能将操作的成本与其调用方关联。
而虚拟线程既保持与平台的设计兼容,同时又能最佳地利用硬件从而不影响可伸缩性。虚拟线程是由 JDK 而非操作系统提供的线程的轻量级实现:
- 虚拟线程是没有绑定到特定操作系统线程的线程。
- 平台线程是以传统方式实现的线程,作为围绕操作系统线程的简单包装。
这里我们引入一条重要法则:
- 利特尔法则(Little’s Law):对于给定的延迟 ,并发性与吞吐量成正比增长
- 延迟:请求处理持续时间
- 并发性:应用程序同时处理的请求数
- 吞吐量:到达速率
#两种并发风格
#**thread-per-request style **
-
服务器应用程序通常处理彼此独立的并发用户请求,因此应用程序通过在整个请求持续期间为该请求分配一个线程来处理请求是有意义的。这种按请求执行线程的风格易于理解、易于编程、易于调试和配置,因为它使用平台的并发单元来表示应用程序的并发单元。
-
服务器应用程序的可伸缩性受到利特尔法则(Little’s Law)的支配,该定律关系到延迟、并发性和吞吐量: 对于给定的请求处理持续时间(延迟) ,**应用程序同时处理的请求数(并发性)必须与到达速率(吞吐量)**成正比增长。
例如,假设一个平均延迟为 50ms 的应用程序通过并发处理 10 个请求实现每秒 200 个请求的吞吐量。为了使该应用程序的吞吐量达到每秒 2000 个请求,它将需要同时处理 100 个请求。如果在请求持续期间每个请求都在一个线程中处理,那么为了让应用程序跟上,线程的数量必须随着吞吐量的增长而增长。
-
不幸的是,可用线程的数量是有限的,因为 JDK 将线程实现为操作系统(OS)线程的包装器。操作系统线程代价高昂,因此我们不能拥有太多线程,这使得实现不适合每个请求一个线程的 style 。
-
如果每个请求在其持续时间内消耗一个线程,从而消耗一个 OS 线程,那么线程的最大数量会受到CPU的限制。JDK 当前的线程实现将应用程序的吞吐量限制在远低于硬件所能支持的水平。即使在线程池中也会发生这种情况,因为池有助于避免启动新线程的高成本,但不会增加线程的总数。
#**thread-sharing style **
- 一些希望充分利用硬件的开发人员已经放弃了**每个请求一个线程(thread-per-request)的 style ,转而采用线程共享(thread-sharing )**的 style 。
- 请求处理代码不是从头到尾处理一个线程上的请求,而是在等待 I/O 操作完成时将其线程返回到一个池中,以便该线程能够处理其他请求。这种细粒度的线程共享(其中代码只在执行计算时保留一个线程,而不是在等待 I/O 时保留该线程)允许大量并发操作,而不需要消耗大量线程。
- 虽然它消除了操作系统线程的稀缺性对吞吐量的限制,但代价很高: 它需要**异步风格 **,采用一组独立的 I/O 方法,这些方法不等待 I/O 操作完成,而是在以后将其完成信号发送给回调。如果没有专门的线程,开发人员必须将请求处理逻辑分解成小的阶段,通常以 lambda 表达式的形式编写,然后将它们组合成带有 API 的顺序管道。因此,它们放弃了语言的基本顺序组合运算符,如循环和 try/catch 块。
- 在异步风格中,请求的每个阶段可能在不同的线程上执行,每个线程以交错的方式运行属于不同请求的阶段。这对于理解程序行为有着深刻的含义:
- 堆栈跟踪不提供可用的上下文
- 调试器不能单步执行请求处理逻辑
- 分析器不能将操作的成本与其调用方关联。
- 当使用 Java 的流 API 在短管道中处理数据时,组合 lambda 表达式是可管理的,但是当应用程序中的所有请求处理代码都必须以这种方式编写时,就有问题了。这种编程风格 与 Java 平台不一致,因为应用程序的并发单元(异步管道)不再是平台的并发单元。
#对比
| thread-per-request style | **thread-sharing style ** | |
|---|---|---|
| 优点 | 使用平台的并发单元来表示应用程序的并发单元。 与 Java 平台的设计相协调,易于理解、易于编程、易于调试和配置 |
减小了操作系统线程的稀缺性对吞吐量的限制。 这种细粒度的线程共享允许大量并发操作,而不需要消耗大量线程,提高可伸缩性 |
| 缺点 | 可用线程的数量是有限的,操作系统线程代价高昂,因此我们不能拥有太多线程。 JDK 当前的线程实现将应用程序的吞吐量限制在远低于硬件所能支持的水平 |
应用程序的并发单元(异步管道)不再是平台的并发单元。请求的每个阶段可能在不同的线程上执行,每个线程以交错的方式运行属于不同请求的阶段 难以跟踪堆栈、单步调试 |
#使用虚拟线程保留thread-per-request style
为了使应用程序能够在与平台保持和谐的同时进行扩展,我们应该通过更有效地实现线程来努力保持每个请求一个线程的风格。
操作系统无法更有效地实现 OS 线程,因为不同的语言和运行时以不同的方式使用线程堆栈。然而,Java 运行时实现 Java 线程的方式可以切断它们与操作系统线程之间的一一对应关系。正如操作系统通过将大量虚拟地址空间映射到有限数量的物理 RAM 而给人一种内存充足的错觉一样,Java 运行时也可以通过将大量虚拟线程映射到少量操作系统线程而给人一种线程充足的错觉。
- 虚拟线程是没有绑定到特定操作系统线程的线程。
- 平台线程是以传统方式实现的线程,作为围绕操作系统线程的简单包装。
thread-per-request 样式的应用程序代码可以在整个请求期间在虚拟线程中运行,但是虚拟线程只在 CPU 上执行计算时使用操作系统线程。其结果是与异步样式相同的可伸缩性,除了它是透明实现的:
当在虚拟线程中运行的代码调用 Java.* API 中的阻塞 I/O 操作时,运行时执行一个非阻塞操作系统调用,并自动挂起虚拟线程,直到稍后可以恢复。
对于 Java 开发人员来说,虚拟线程是创建成本低廉、数量几乎无限多的线程。硬件利用率接近最佳,允许高水平的并发性,从而提高吞吐量,而应用程序仍然与 Java 平台及其工具的多线程设计保持协调。
#虚拟线程的意义
虚拟线程同时聚合了两个风格的优点:
- thread-per-request style:与 Java 平台设计相协调,易于跟踪、调试
- **thread-sharing style **:消除了操作系统线程的稀缺性对吞吐量的限制,允许大量并发,提高可伸缩性
虚拟线程是廉价和丰富的,因此永远不应该被共享(即使用线程池): 应该为每个应用程序任务创建一个新的虚拟线程。
因此,大多数虚拟线程的寿命都很短,并且具有浅层调用堆栈,执行的操作只有单个 HTTP 客户端调用或单个 数据库查询那么少。相比之下,平台线程是重量级和昂贵的,因此经常必须共享。它们往往是长期存在的,具有深度调用堆栈,并且在许多任务之间共享。
总之,虚拟线程保留了可靠的 thread-per-request style ,这种风格与 Java 平台的设计相协调,同时又能最佳地利用硬件。虚拟线程不仅可以帮助应用程序开发人员ーー它们还可以帮助框架设计人员提供易于使用的 API,这些 API 与平台的设计兼容,同时又不影响可伸缩性。
实践
#环境配置
#IDEA
IDEA至少要更新到2022.2
#Project Structure


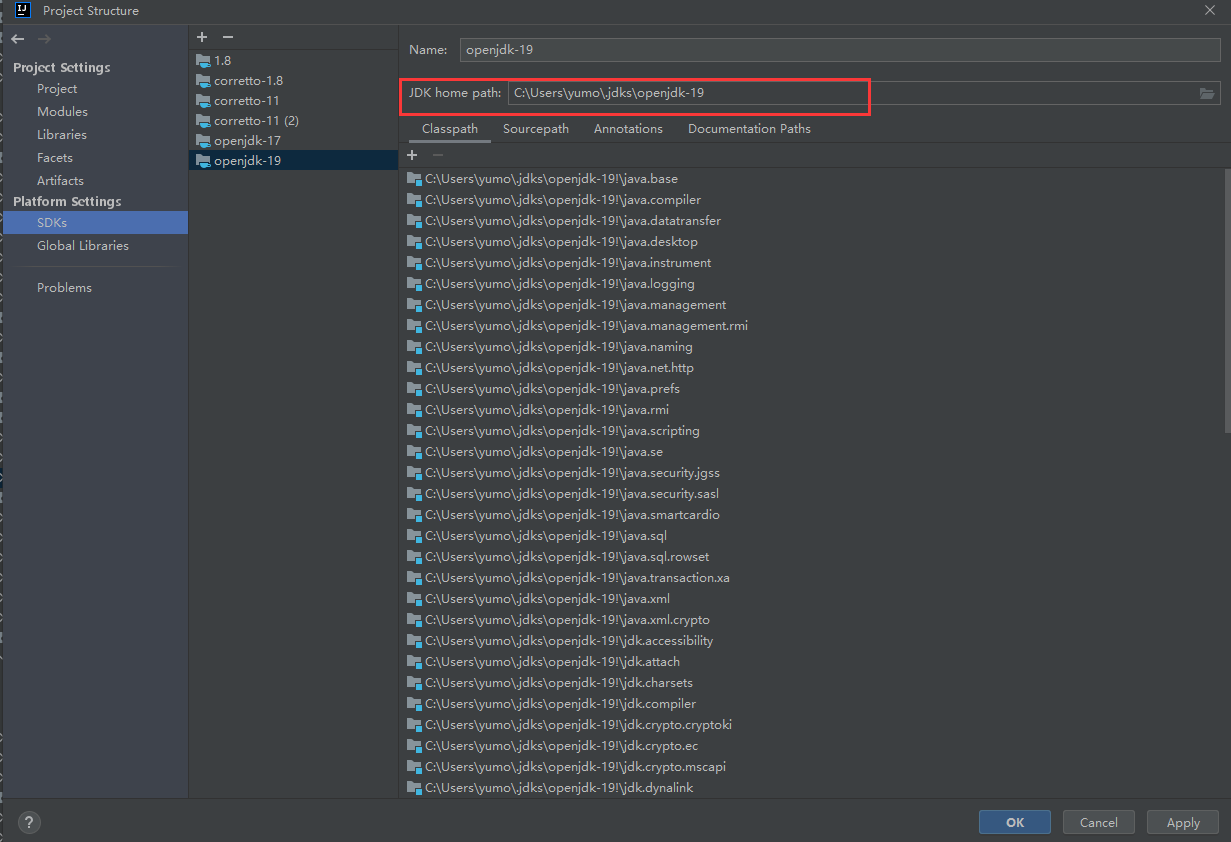
#Settings

#Maven
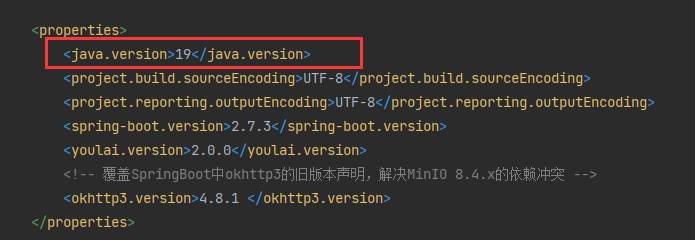
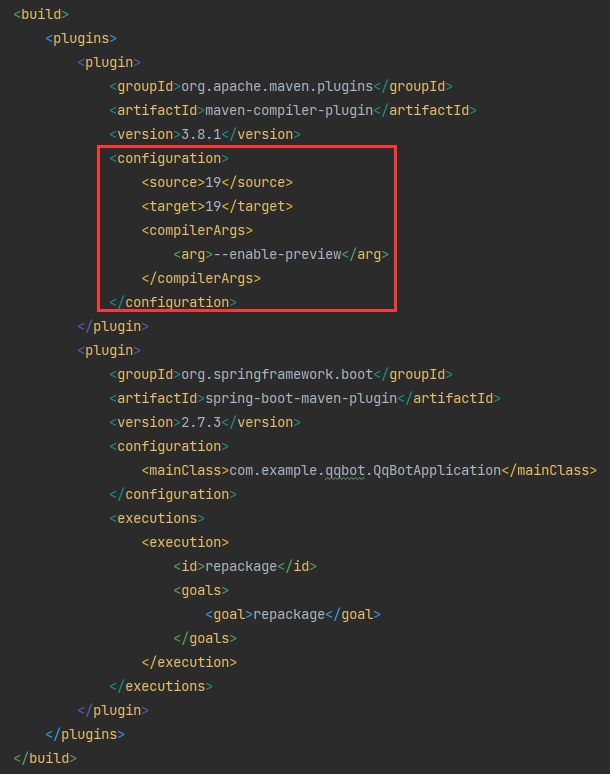
#原生API
#使用方式
创建虚拟线程并分配任务只需两步:
-
创建 executorService:
ExecutorService executorService = Executors.newVirtualThreadPerTaskExecutor() -
调用 submit 方法提交任务:
executorService.submit( task )
#对比实验
实验设备
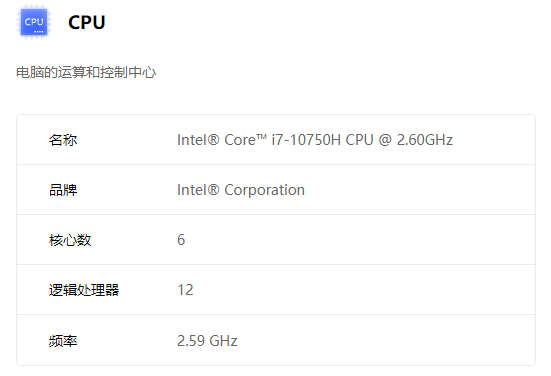
最大平台线程数:12
最大内存:16G
#实验一:测试n个执行1s的线程总运行时间
#线程池共享平台线程
#代码
1 |
|
#结果

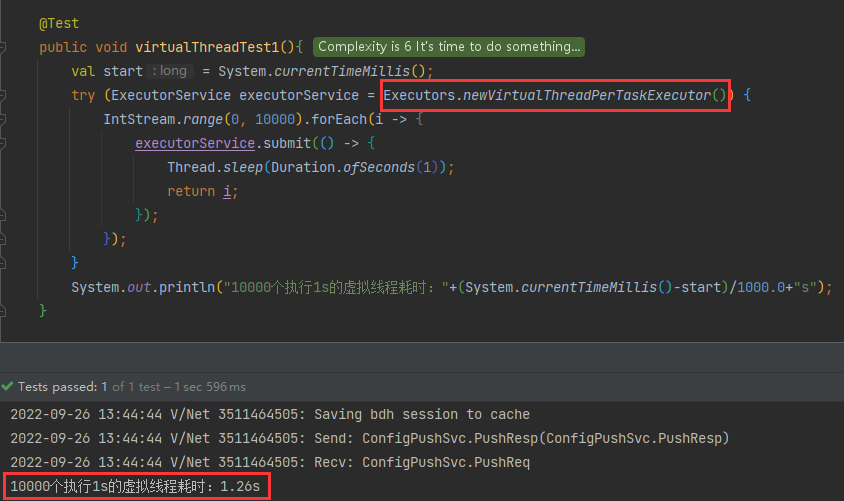
#虚拟线程
#代码
1 |
|
#结果
#统计结果
线程池共享平台线程
| 测试次数i \ 耗时(s) | 10,000并发量 | 100,000并发量 | 1,000,000并发量 |
|---|---|---|---|
| 1 | 1.926 | 11.693 | 50.337 |
| 2 | 1.981 | 11.377 | 41.581 |
| 3 | 2.051 | 10.364 | 45.999 |
| 4 | 1.919 | 10.487 | 46.313 |
| 5 | 2.203 | 10.851 | 47.274 |
| 平均值 | 2.106 | 10.954 | 46.301 |
虚拟线程
| 测试次数i \ 耗时(s) | 10,000并发量 | 100,000并发量 | 1,000,000并发量 | 5,000,000并发量 |
|---|---|---|---|---|
| 1 | 1.054 | 1.614 | 18.243 | 38.822 |
| 2 | 1.057 | 1.743 | 18.407 | 35.669 |
| 3 | 1.051 | 1.663 | 19.101 | 40.235 |
| 4 | 1.043 | 1.593 | 17.219 | 36.156 |
| 5 | 1.044 | 1.706 | 18.064 | 37.245 |
| 平均值 | 1.050 | 1.664 | 18.207 | 37.625 |
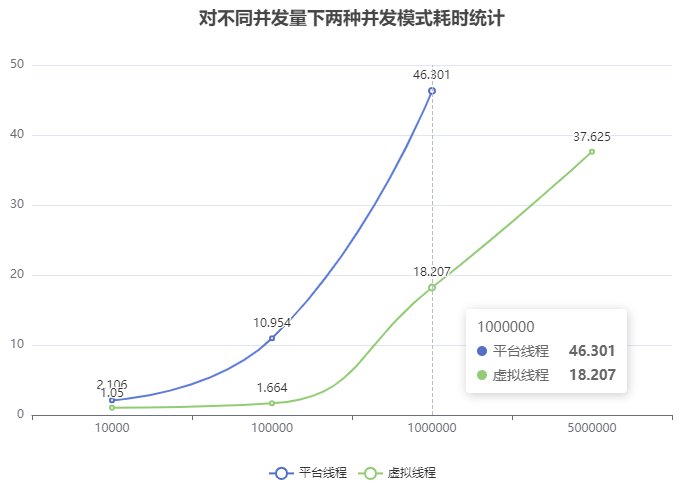
可以看到,随着并发量越来越大,线程池共享平台线程模式和对每个任务创建一个新的虚拟线程模式二者的耗时差距越来越大。
相比于用线程池共享平台线程的异步,虚拟线程显著提高了硬件利用率,从而大幅提高吞吐量
根据利特尔法则:时延一定,并发性跟吞吐量成正相关
由此得出结论:在硬件条件相同、时延一定的情况下,虚拟线程的并发性远超线程池共享模式
#整合SpringBoot
#Bean创建
VirtualThreadConfig.class
1 | /** |
这样我们就可以在springboot启动时就创建好唯一的一个executorService
例如,在Controller层获取executorService:
- 请求方法内首先对整个代码块创建一个新的虚拟线程:实现多请求并发执行
- 然后对for循环内10000个互相独立的代码创建10000个虚拟线程:对于调用方来说,他从发起请求到获取响应的时间从原来的n变为1
1 |
|
#AOP注解驱动开发
#手动传入任务的弊端
调用一个方法时,为该方法创建另外一个新的虚拟线程,我们将此过程抽象为对该方法的一种增强。
在上面我们想要给一个任务创建一个虚拟线程,需要如下步骤:
- 导入
executorServicebean - 调用
executorService.submit( task )
但这种方式过于繁琐,需要将所有原子任务抽象为方法,将这些方法的整个方法体用lambda表达式放入executorService.submit( ...... )中。
#优化思路
对此,我们设想有一个这样的注解:
- 将这个注解标注在一个方法上,当该方法被执行时,会自动为其新开一个虚拟线程供其执行。
而为被执行方法创建一个新线程这一功能,我们可以将其抽象为对该方法的增强。
#创建注解
@VirtualThread
1 | import java.lang.annotation.*; |
#创建AOP
VirtualThreadAspect.class
1 | package com.example.qqbot.aop; |
结论:
- AOP注解驱动开发能够应用于并发请求执行
- AOP注解驱动开发无法应用于方法内嵌套并发执行,但依然可以用
executorService.submit( task )
#实验二:验证AOP注解驱动开发能够应用于并发请求执行
实验设备:使用Jmeter在本机上对本地接口并发测试,当Jmeter发送并发请求时,本机CPU压力变大,能分配给本地接口执行的平台线程越来越少。
观察三种方法在硬件压力越来越大的情况下吞吐量随并发请求数和时间的变化。
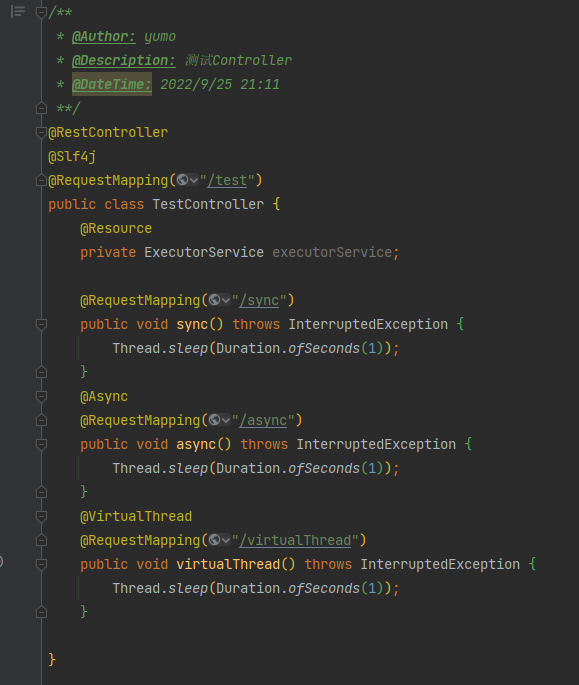
对照组:sync方法,同步执行
100,000次请求

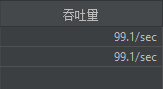
实验组1:async方法,异步执行
1,000,000次请求

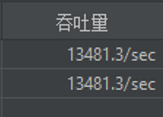
实验组2:virtualThread方法,虚拟线程执行
1,000,000次请求

重复以上操作,统计得下表:
| 处理方式\请求结束时吞吐量(/sec)\并发请求数 | 10,000 | 100,000 | 1,000,000 |
|---|---|---|---|
| 同步sync | 99.0 | 99.1 | 99.1 |
| 异步async | 9842.3 | 24197.7 | 13481.3 |
| 虚拟线程virtualThread | 9842.5 | 25647.6 | 23691.1 |
由上表得出结论:
- 虚拟线程和线程池共享一开始的吞吐量接近,随着并发量和时间的增加,虚拟线程开始显著优于线程池共享。
#注意事项
@VirtualThread和@Async因为底层皆使用aop,所以同一个类中的方法不能互相调用,其他使用aop的注解如@Transaction同样:- 原因:aop底层使用动态代理,对该类生成其代理类,由代理对象执行原对象的方法1;而同一个类中被方法1调用的方法2仍然是由原对象执行,无法生成其代理类从而无法实现增强逻辑。
- 解决办法:
- 使用
springcontext获取该类的bean,用该bean对象显式调用同类中的其他方法。 - 使用
executorService.submit( task )手动调用该方法。
- 使用
@VirtualThread和@Async一样,被标注的方法的返回值必须为void或Future类型- 原因:增强逻辑返回的是
Future对象。 - 解决办法:如要调用返回值为其他类型的方法,可以用
executorService.submit( task )手动调用该方法
- 原因:增强逻辑返回的是
推广
由上述例子启发,将以下概念推广:
- 客户端 -> 方法的调用方
- 发起请求 -> 调用方法
- 返回响应 -> 方法返回
- 服务端 -> 被调用方
运用上述广义概念,我们可得出以下定义:
- 原子任务:由一个复合任务划分成的有限个、独立的、最小的子任务之一。记作
a - 复合任务:由有限次个原子任务组成的任务
- 主原子任务:接收请求到返回响应的原子任务。记作
main(a)
对于请求到响应的这一过程所耗费的时间:
-
若不使用虚拟线程,则为同步执行:耗费所有原子任务各自耗费时间的总和(
Σa) -
从服务器的角度来看:耗费原子任务中最长的那一个的时间(
max(a)) -
从客户端的用户反馈角度来看:耗费主原子任务时间(
main(a))
如下图所示,一个向数据库增加数据的请求。
- 对于用户来说,从请求到响应只耗时
t2,即主原子任务时间
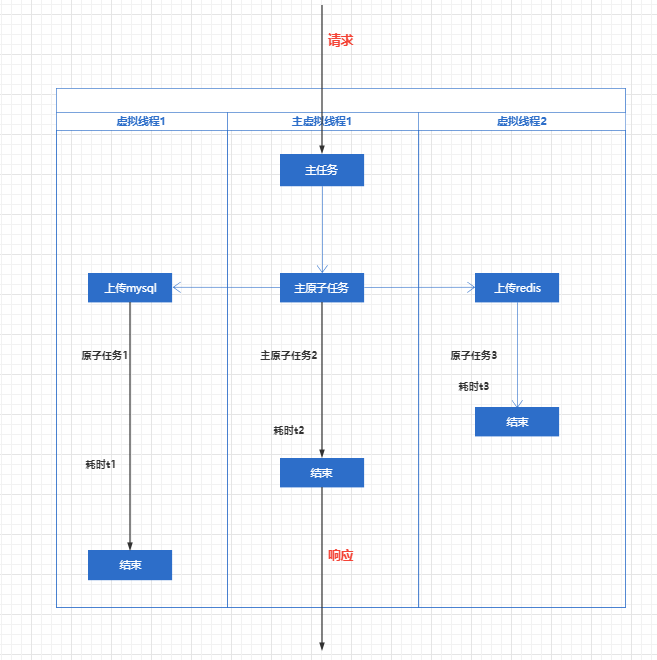
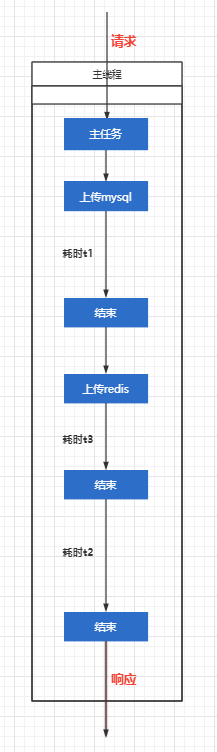
而如果是原本的管道式同步执行:
- 对于用户来说,从请求到相应耗时
t1 + t2 + t3
结语
目前本人只能简单地用aop实现注解驱动,但是它还可以扩展出类似 @EnableAsync 的 @EnableVirtual,且没有进行更细致的性能优化
期待未来不久市场上jdk19的虚拟编程能够普及
参考文章
JEP 425: Virtual Threads (Preview) (openjdk.org)
可以使用github action来进行cicd,这样每次只需要push后即可自动重新部署
cicd.yml
1 | name: CI |