Harness Engineering
#What Harness Actually Means
#Core Concepts
What is a harness: Everything in the engineering infrastructure outside the model weights.
OpenAI distills the engineer’s core job into three things:
- designing environments
- expressing intent
- building feedback loops.
The repo is the single source of truth: Anything the agent can’t see, for all practical purposes, doesn’t exist. OpenAI treats the repo as the “system of record” — all necessary context must live there, through structured files and clear directory organization.
Give a map, not a manual: OpenAI’s experience — AGENTS.md should be a directory page, not an encyclopedia. Around 100 lines is enough. If it doesn’t fit, split it into the docs/ directory and let the agent read on demand.
Constrain, don’t micromanage: A good harness uses executable rules to constrain the agent, rather than enumerating instructions one by one. OpenAI says “enforce invariants, don’t micromanage implementation”; Anthropic found that agents confidently praise their own work, and the solution is to separate “the person who does the work” from “the person who checks the work.”
Remove components one at a time: To quantify the value of each harness component, remove them one at a time and see which removal causes the biggest performance drop. Anthropic used this method and found that as models get stronger, some components stop being critical — but new ones always emerge.
#The Five-Subsystem Harness Model
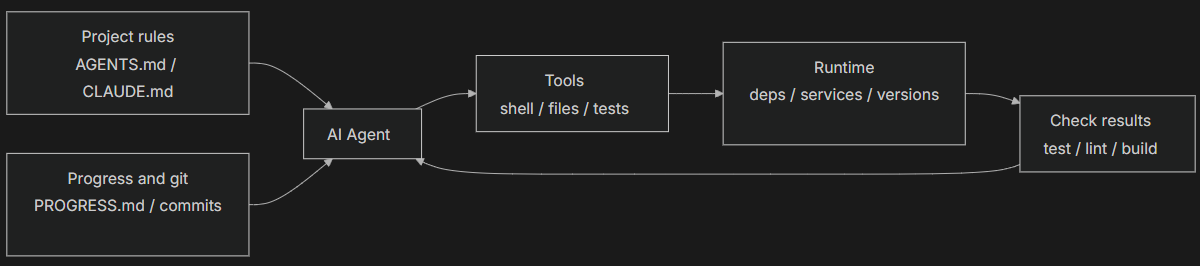
Instruction subsystem (recipe shelf): Create AGENTS.md (or CLAUDE.md) containing
- a project overview
- purpose (one sentence)
- tech stack
- versions (Python 3.11, FastAPI 0.100+, PostgreSQL 15),
- first-run commands (
make setup,make test), - non-negotiable hard constraints (“All APIs must use OAuth 2.0”)
- links to more detailed documentation.
Tool subsystem (knife rack): Ensure the agent has sufficient tool access. Don’t disable shell for “security” — if the agent can’t even run pip install, how is it supposed to work? But don’t open everything either — follow least-privilege principles.
Environment subsystem (stove): Make the environment state self-describing. Use pyproject.toml or package.json to lock dependencies, .nvmrc or .python-version for runtime versions, Docker or devcontainers for reproducibility.
State subsystem (prep station): Long tasks need progress tracking. Use a simple PROGRESS.md file recording: what’s done, what’s in progress, what’s blocked. Update before each session ends, read when the next session starts.
Feedback subsystem (quality check window): This is the highest-ROI subsystem. Explicitly list verification commands in AGENTS.md:
1 | Verification commands: |
Diagnosing harness quality: Use “isometric model control.” Keep the model fixed, remove subsystems one at a time, measure which removal causes the biggest performance drop. That’s your bottleneck — focus your effort there. Like finding the bottleneck in a kitchen: take away the recipe shelf and see how much slower things get, shut off the stove and see the impact.
#Key Takeaways
- Harness = Instructions + Tools + Environment + State + Feedback. Five subsystems, like a kitchen’s five functional areas — all essential.
- If it’s not model weights, it’s harness. Your harness determines how much model capability gets realized.
- Among the five subsystems, the feedback subsystem usually has the lowest investment and highest return. Get your verification commands right first — the quality check window is the most worthwhile upgrade.
- Use “isometric model control” to quantify each subsystem’s marginal contribution — don’t go by gut feeling.
- Harness rots like code does. Audit regularly, pay down harness debt like you pay down technical debt.
#Make the Repository Your Single Source of Truth
#Knowledge Visibility

How do you test whether your map is good enough? Run a “cold-start test”: open a brand new agent session using only repo contents, and see if it can answer five basic questions:
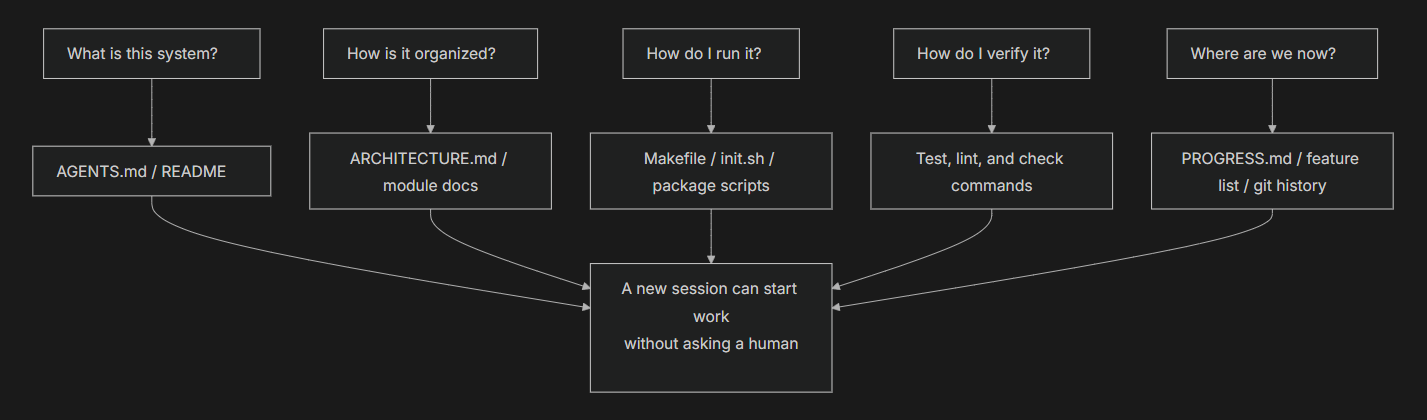
If it can’t answer, the map has blank spots. Where the map is blank, the agent guesses — wrong guesses become bugs, excessive guessing wastes context. And every new session guesses all over again. The cost of guessing is always higher than the cost of drawing the map properly in the first place.
#Core Concepts
- Knowledge Visibility Gap: The proportion of total project knowledge that’s NOT in the repository. The bigger the gap, the higher the agent’s failure rate. How much implicit knowledge about this project lives in your head? Count it all, then see how much made it into the repo — the difference is your visibility gap.
- System of Record: The code repository as the authoritative source for project decisions, architecture constraints, execution state, and verification standards. The repo has the final word, nowhere else counts. Like a map that marks “road closed” — you won’t go down that road. But if that information only exists in Old Zhang’s head, you have to ask Old Zhang every time.
- Cold-Start Test: The five questions above. How many it can answer is how complete your map is.
- Discovery Cost: How much context budget the agent burns to find a key piece of information in the repo. The more hidden the information, the higher the discovery cost, and the less budget left for the actual task. Hiding critical information in a README ten directory levels deep is like locking the fire extinguisher in a basement safe — it exists, but you can’t find it when you need it.
- Knowledge Decay Rate: The proportion of knowledge entries that become stale per unit of time. Documentation going out of sync with code is the biggest enemy — worse than no documentation at all.
- ACID Analogy: Applying database transaction principles (Atomicity, Consistency, Isolation, Durability) to agent state management. We’ll expand on this below.
#How to Draw a Good Map
Principle 1: Knowledge lives next to code. A rule about API endpoint authentication belongs next to the API code, not buried in a giant global document. Put a short doc in each module directory explaining that module’s responsibilities, interfaces, and special constraints. Like library shelf labels — you want history books, go straight to the shelf marked “History.” No need to search the entire library.
Principle 2: Use a standardized entry file. AGENTS.md (or CLAUDE.md) is the agent’s “landing page.” It doesn’t need to contain all information, but it must let the agent quickly answer three questions: “What is this project,” “How do I run it,” and “How do I verify it.” 50-100 lines is enough.
Principle 3: Minimal but complete. Every piece of knowledge should have a clear use case. If removing a rule doesn’t affect the agent’s decision quality, that rule shouldn’t exist. But every question from the cold-start test must have an answer. This is a delicate balance — not too much, not too little, just enough.
Principle 4: Update with code. Bind knowledge updates to code changes. The simplest approach: put architecture docs in the corresponding module directory. When you modify code, you naturally see the doc. After code changes, CI can remind you to check if docs need updating.
Concrete repo structure:
1 | project/ |
#Split Instructions Across Files
#Core Concepts
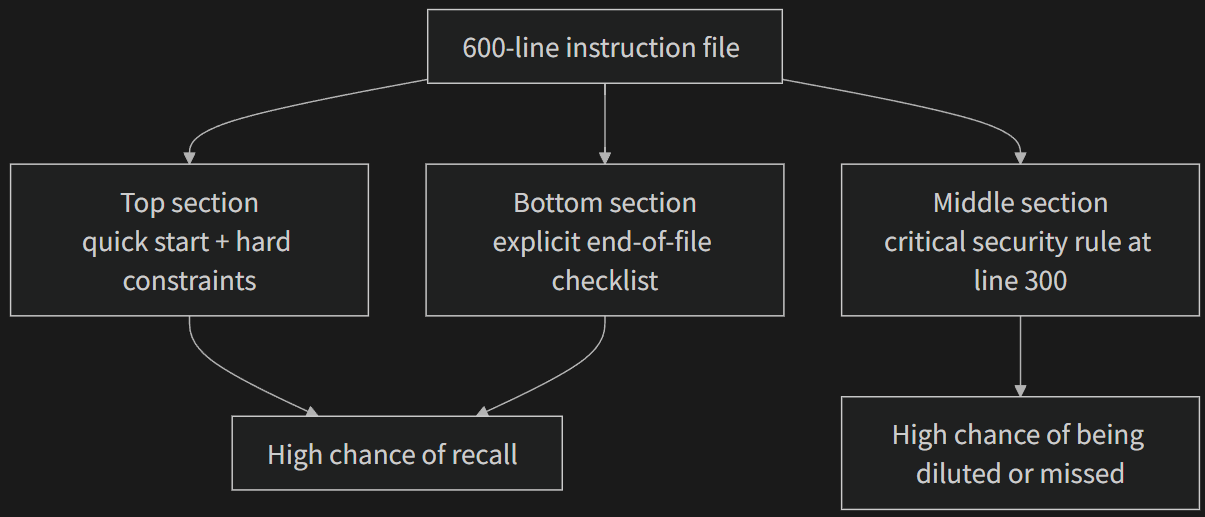
- Instruction Bloat: When an instruction file occupies more than 10-15% of the context window, it starts crowding out budget for code reading and task reasoning. A 600-line
AGENTS.mdmight consume 10,000-20,000 tokens — that’s 8-15% of a 128K window eaten before the agent even starts. - Lost in the Middle Effect: Liu et al.'s 2023 research proved that LLMs use information in the middle of long texts significantly less effectively than information at the beginning or end. A critical constraint buried at line 300 of a 600-line file has a very high probability of being effectively ignored.
- Instruction Signal-to-Noise Ratio (SNR): The proportion of instructions in a file that are relevant to the current task. Being forced to read 50 lines of deployment instructions during a bug fix — that’s low SNR.
- Routing File: A short entry file whose core function is pointing the agent to more detailed docs, not containing everything itself. 50-200 lines is plenty.
- Progressive Disclosure: Give overview information first, detailed information when needed. Good harness design is like good UI design — don’t dump all options on the user at once.
- Priority Ambiguity: When all instructions appear in the same format and location, the agent can’t distinguish non-negotiable hard constraints from suggestive soft guidelines.
#Instruction Architecture

#How to Split
Core principle: keep frequently-needed information at hand, tuck away occasionally-needed information, and leave behind what you’ll never use.
The entry file AGENTS.md stays at 50-200 lines, containing only the most frequently used items — project overview (one or two sentences), first-run commands (make setup && make test), global hard constraints (no more than 15 non-negotiable rules), and links to topic documents (one-line description + applicability condition).
1 | # AGENTS.md |
Each topic document is 50-150 lines, organized by subject in the docs/ directory or next to the corresponding module. The agent only reads them when needed. Like packing cubes in a suitcase — underwear in one cube, toiletries in another, chargers in a third. Finding things doesn’t require emptying the whole bag.
Some information is better placed directly in the code — type definitions, interface comments, explanations in config files. The agent naturally sees these when reading code, no need to duplicate in instructions.
Every instruction should have
- a source (“why was this rule added?”)
- an applicability condition (“when is this rule needed?”)
- an expiry condition (“under what circumstances can this rule be removed?”).
Audit regularly, remove outdated, redundant, and contradictory entries. Manage your instructions like you manage code dependencies — unused dependencies should be deleted, otherwise they just slow the system down.
If an instruction must be in the entry file, put it at the top or bottom — never the middle. The “lost in the middle” effect tells us that LLMs use information at the extremes significantly better than in the center. But the better approach is to move instructions to topic documents for on-demand loading.
Both OpenAI and Anthropic implicitly support the splitting approach. OpenAI says entry files should be “short and routing-oriented,” Anthropic says long-running agent control information should be “concise and high-priority.” Both are saying the same thing: don’t stuff everything into one file. A suitcase needs organizing, not just brute-force cramming.
#Initialize Before Every Agent Session
#Initialization Lifecycle

#Core Concepts
- Initialization Phase: The first phase in the agent’s lifecycle — no feature implementation, only establishing prerequisites for all subsequent implementation phases. The output isn’t code, it’s infrastructure.
- Bootstrap Contract: The conditions under which a project can be unambiguously operated by a fresh agent session — can start, can test, can see progress, can pick up next steps. Four conditions, all required.
- Cold Start vs Warm Start: Cold start is from an empty directory where the agent must guess project structure; warm start is from a template or existing project where infrastructure is already in place. Warm start far outperforms cold start — like starting work on a site with running water and electricity versus beginning from a barren wasteland.
- Handoff Readiness: The project is in a state at any given moment where a fresh agent can take over. No verbal explanation needed — just repo contents.
- Time to First Verification: The time from project start until the first feature point passes verification. This is the core metric for measuring initialization efficiency.
- Downstream Usability: The best measure of initialization quality — the proportion of subsequent sessions that can successfully execute tasks without relying on implicit knowledge.
#How to Do Initialization Right
Treat initialization as a dedicated phase. The first session does only initialization — no business feature code at all. Initialization produces:
1. Runnable environment. The project starts, dependencies are installed, no environment issues. Foundation poured, no cracks.
2. Verifiable test framework. At least one example test passes. This proves the test framework itself is properly configured — like standing a pillar on the foundation to prove it can bear weight.
3. Bootstrap contract document. A clear document telling subsequent sessions:
1 | # Initialization Contract |
4. Task breakdown. Split the entire project into an ordered task list, each task with clear acceptance criteria:
1 | # Task Breakdown |
5. Git commit as checkpoint. After initialization completes, commit a clean checkpoint. All subsequent work starts from this checkpoint.
Warm start strategy: Don’t start from an empty directory. Use a project template (create-react-app, fastapi-template, etc.) to preset standard directory structure, dependency configuration, and test framework. Bake common initialization steps into the template, leaving only project-specific initialization work. Like starting work on a site with running water and electricity — ten thousand times better than beginning from a barren wasteland.
Initialization completion criteria: Not “how much code was written,” but whether the bootstrap contract’s four conditions are met — can start, can test, can see progress, can pick up next steps. Use this checklist to validate initialization:
1 | ## Initialization Acceptance Checklist |
#Key Takeaways
- Initialization and implementation have different optimization targets — mixing them just drags both down. Pour the foundation first, then build the walls.
- Initialization’s output isn’t code, it’s infrastructure: runnable environment, verifiable tests, bootstrap contract, task breakdown.
- Validate initialization with the bootstrap contract’s four conditions: can start, can test, can see progress, can pick up next steps.
- Warm start beats cold start. Use project templates to preset standardized infrastructure.
- Time invested in initialization is fully recovered in the next 3-4 sessions. This isn’t extra cost — it’s upfront investment. The more solid the foundation, the faster the building goes up.
#Draw Clear Task Boundaries for Agents
#WIP=1 Workflow

#Core Concepts
- Overreach: The agent activates more tasks in a single session than optimal. It’s quantifiable — doing 5 features with 0 passing end-to-end is overreach.
- Under-finish: The ratio of tasks that pass end-to-end verification, out of all activated tasks, falls below threshold. Code written but tests not passing is under-finish.
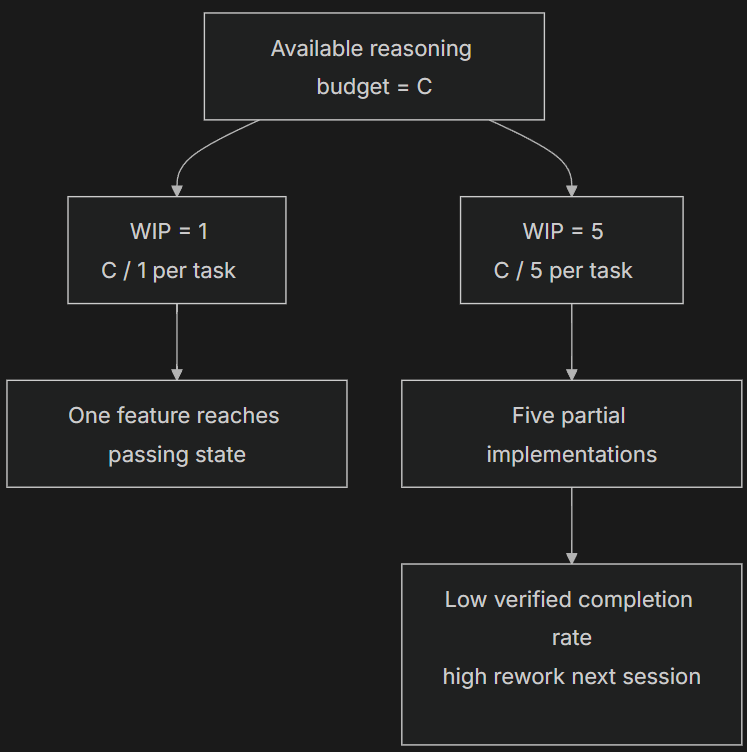
- WIP Limit (Work-in-Progress Limit): From Kanban methodology. Core idea: limit how many tasks are in-flight at once. For agents, WIP=1 is the safest default — finish one before starting the next. Like a buffet — don’t pile your plate, finish one plate then go back for the next.
- Completion Evidence: The verifiable condition a task must satisfy to move from “in progress” to “done.” Without this, agents substitute “the code looks fine” for “the behavior passes tests.”
- Scope Surface: A DAG structure where each node is a work unit and edges are dependencies. States are limited to four: not_started, active, blocked, passing.
- Completion Pressure: The constraining force the harness exerts through WIP limits and completion evidence requirements, forcing the agent to finish the current task before starting a new one.
#Overreach and Under-finish Are Symbiotic
These two problems aren’t independent — they amplify each other. Overreach dilutes attention, diluted attention causes under-finish, and the half-finished code left behind increases system complexity, which further drives overreach in the next task. A vicious cycle.
In Kanban terms: Little’s Law tells us L = lambda * W. If work-in-progress L is too high (doing too many things at once), the lead time W for each task inevitably increases. For agents, this means each feature takes longer from start to verified completion, and the probability of failure grows.
This is an old problem in the human world too — Steve McConnell documented in Rapid Development that scope creep is the leading cause of project failure. But humans at least have the intuition of “I’ve done enough.” Agents have none. Generating the next idea costs the model almost nothing in extra tokens — writing “let me fix this too while I’m here” barely registers — but every additional modification dilutes the agent’s attention. Like a buffet where each extra plate has near-zero marginal cost, but your stomach only has so much capacity.
#How to Do It Right
#1. Enforce WIP=1
This is the most direct and effective method. In your harness, tell the agent explicitly: only one task is allowed in “active” status at any time. In Claude Code’s CLAUDE.md or Codex’s AGENTS.md, write:
1 | ## Work Rules |
Like eating at a buffet — one plate at a time, finish it before going back for more.
#2. Define Explicit Completion Evidence for Every Task
Done is not “code is written” — it’s “behavior verification passes.” In your feature list, every entry needs a verification command:
1 | F01: User Registration |
#3. Externalize the Scope Surface
Use a machine-readable file (JSON or Markdown) to record all task states. Any new session can read this file and immediately know: which task is active? What behavior counts as done? What verifications have passed?
#4. Monitor Verified Completion Rate
The harness should continuously track VCR (Verified Completion Rate) = verified tasks / activated tasks. Block new task activations when VCR < 1.0.
#Key Takeaways
- WIP=1 is the default safe setting for agent harnesses — finish one, then start the next; don’t try to parallelize. You can’t become fat in one bite.
- Completion evidence must be executable — “the code looks fine” doesn’t count; “curl returns 201” does.
- The scope surface must be externalized as a file — not just mentioned in conversation, but recorded in a machine-readable format in the repo.
- Overreach and under-finish are symbiotic — solving one solves the other.
- “Do less but finish” always beats “do more but leave half-done” — agent code lines and feature completion rate are negatively correlated. Quality always beats quantity.
#Use Feature Lists to Constrain What the Agent Does
#Feature State Machine
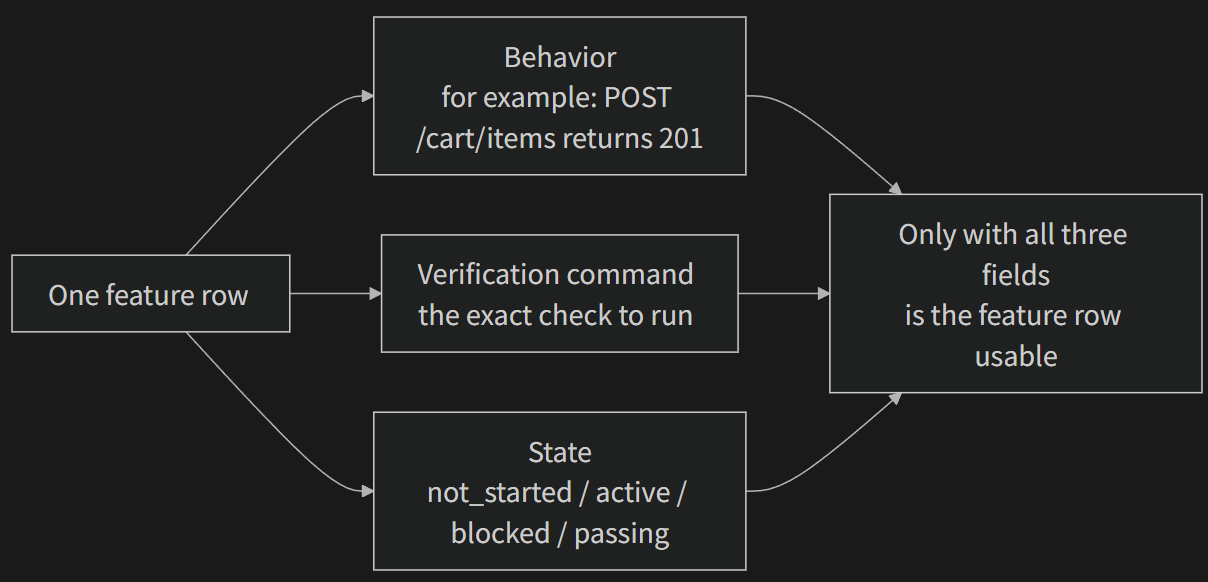

#Core Concepts
- Feature lists are harness primitives: Not “optional planning tools,” but foundational data structures that all other harness components depend on. Like database table structures — you can’t say “let’s skip primary keys.”
- Triple structure: Each feature item is a
(behavior description, verification command, current state)triple. Missing any element makes the item incomplete. - State machine model: Each feature item has four states —
not_started,active,blocked,passing. State transitions are controlled by the harness, not freely changed by the agent. - Pass-state gating: The only way a feature moves from
activetopassingis by verification command executing successfully. This is irreversible — oncepassing, it can’t go back. Like passing an exam means you passed, you can’t retroactively change the score. - Single source of truth: All information about “what needs to be done” must derive from one feature list. No contradictions between the feature list and conversation history.
- Back-pressure: The number of features that haven’t passed yet is the pressure the harness exerts on the agent. Zero pressure = project complete.
#Why Feature Lists Must Be “Primitives”
Documents are for humans to read; primitives are for systems to execute. Documents can be ignored; primitives can’t be bypassed.
Think of it like database trigger constraints vs. application-layer checks: the former is enforced by the database engine, no SQL can skip it; the latter depends on application code correctness and can be accidentally bypassed. Feature lists as harness primitives are Specifically, the feature list serves four harness components:
- Scheduler: Reads states, picks the next
not_startedfeature. Like a factory production planning system. - Verifier: Executes verification commands, decides whether to allow state transitions. Like quality inspection.
- Handoff reporter: Automatically generates session handoff summaries from the feature list. Like an automatic shift-change report.
- Progress tracker: Tallies state distribution, provides project health metrics. Like a dashboard.
#How to Do It Right
#1. Define a Minimal Feature List Format
You don’t need a complex system — a structured Markdown or JSON file works. The key is every entry must have the triple:
1 | { |
#2. Let the Harness Control State Transitions
The agent can’t directly change a feature’s state to passing. It can only submit a verification request; the harness executes the verification command and decides whether to allow the transition. This is “pass-state gating.”
#3. Write the Rules in CLAUDE.md
1 | ## Feature List Rules |
#4. Calibrate Granularity
Each feature item should be scoped to “completable in one session.” Too broad and it won’t finish; too narrow and the management overhead grows. “User can add items to cart” is good granularity. “Implement the shopping cart” is too broad. “Create the name field on the Cart model” is too narrow. Like cutting a steak — not the whole piece, and not ground meat.
#Key Takeaways
- Feature lists are the harness’s backbone, not memos for humans. Scheduler, verifier, and handoff reporter all depend on them.
- Every feature item must have the triple: behavior description + verification command + current state. Missing one element makes it incomplete — like a three-legged stool missing a leg.
- State transitions are controlled by the harness — the agent can’t change states on its own. Passing verification = the only upgrade path.
- The feature list is the project’s single source of truth — all “what to do” information derives from one list.
- Calibrate granularity to “completable in one session.”
#Preventing Agents from Declaring Victory Too Early
#The Slippery Slope
Premature completion declarations almost always follow the same pattern: the code looks okay—syntax is correct, logic seems reasonable, and static analysis shows no obvious errors. But the harness doesn’t enforce comprehensive execution verification, so the agent skips actually running it or only runs partial tests. It runs unit tests but skips integration tests; it runs tests but doesn’t check coverage. Ultimately, “the code looks fine” is taken as evidence that “the feature is complete.” And the exam paper is handed in.
Information is lost at every step. From task specifications to code implementation to runtime behavior, every transformation can introduce bias, and every skipped verification exacerbates the information asymmetry.
#Three-Layer Termination Check


#Core Concepts
- Premature Completion Declaration: The agent asserts the task is complete, but unmet correctness specifications still exist. The core issue: the agent judges based on local confidence at the code level, while system-level correctness requires global verification.
- Confidence Calibration Bias: The systematic gap between the agent’s self-reported confidence in completion and the actual completion quality. For complex multi-file tasks, this bias is significantly positive—the agent is always more confident than it actually performs. Just like a student who always overestimates their score after an exam.
- Termination Criteria: A clear, executable set of judgment conditions defined in the harness. The agent must satisfy all conditions before declaring completion. “Done” shifts from a subjective judgment to an objective determination.
- Verification-Validation Dual Gate: The first verification layer checks “did the code correctly implement the specified behavior”; the second validation layer checks “does the system-level behavior meet the end-to-end requirements”. Both must pass to be considered complete.
- Runtime Feedback Signals: Logs, process states, and health checks from program execution. This is the objective basis for the harness to judge completion quality.
- Completion Priority Constraint: First verify functional correctness, then handle performance, and finally address style. Refactoring is forbidden until core functionality is verified.
#Passing Unit Tests ≠ Task Complete
This is the most common trap, and the most dangerous one. The agent wrote the code, ran the unit tests, got all greens, and said “done.” But the design philosophy of unit tests—isolating the tested unit and mocking dependencies—is exactly what makes them incapable of detecting cross-component issues:
Interface Mismatch: The file path passed by the render process to the preload script is a relative path, but the preload script expects an absolute path. Their respective unit tests both used mocks and passed. The issue is only discovered during end-to-end testing. Just like every musician in a band practicing perfectly on their own, only to realize they are in different keys when playing together.
State Propagation Errors: A database migration changes the table schema, but the ORM caching layer still holds cache entries for the old schema. Unit tests provide a fresh mock environment every time, which won’t expose this cross-layer state inconsistency.
Environment Dependency: The code behaves correctly in the test environment (where everything is mocked) but fails in the real environment due to configuration differences, network latency, or service unavailability. Like singing perfectly in the rehearsal room, but encountering audio equipment issues on stage.
#“Refactoring While We’re at It” is Poison to Completion Judgment
Claude Code has a common behavioral pattern: it starts refactoring code, optimizing performance, and improving style before the core functionality has passed verification. Knuth’s quote, “Premature optimization is the root of all evil,” takes on new meaning in the agent scenario—refactoring alters the boundary between verified and unverified code, potentially breaking previously implicitly correct code paths. It’s like re-copying your multiple-choice answers for better formatting before you’ve finished the math essay questions—not only does it waste time, but you might copy them wrong.
#Systematic Bias in Self-Evaluation
Anthropic discovered a deeper failure pattern in their 2026 research: when an agent is asked to evaluate its own work, it systematically provides overly positive evaluations—even when a human observer would consider the quality clearly substandard. This is like asking a student to grade their own exam—they will always be particularly lenient with their own answers.
This issue is especially severe in subjective tasks (such as design aesthetics)—whether a “layout is exquisite” is a judgment call, and the agent reliably skews positive. Even on tasks with verifiable results, the agent’s performance can be hindered by poor judgment.
The solution isn’t to make the agent “more objective”—the same model generating and evaluating inherently favors being generous to itself. The solution is to separate the “worker” from the “checker”. Just like a student shouldn’t grade their own exam—you need an independent grader.
An independent evaluating agent, specifically tuned to be “picky”, is far more effective than having the generating agent evaluate itself. Experimental data from Anthropic:
| Architecture | Runtime | Cost | Core Features Working? |
|---|---|---|---|
| Single Agent (bare run) | 20 mins | $9 | No (game entities unresponsive to input) |
| Three Agents (planner + generator + evaluator) | 6 hours | $200 | Yes (game is fully playable) |
This is the exact same model (Opus 4.5) with the exact same prompt (“build a 2D retro game editor”). The only difference is the harness—from “running bare” to “planner expands requirements → generator implements feature by feature → evaluator performs actual click testing using Playwright”.
#How to Prevent Premature Hand-ins
#1. Externalize Termination Judgment
The completion judgment shouldn’t be made by the agent itself. The harness must independently execute termination validation, using runtime signals as input, not the agent’s confidence. Write this clearly in CLAUDE.md:
1 | ## Definition of Done |
#2. Build a Three-Layer Termination Validation
- Layer 1: Syntax and Static Analysis. Lowest cost, least information, but must pass. This is the bare minimum check—you must spell the words right before we look at anything else.
- Layer 2: Runtime Behavior Verification. Test execution, app startup checks, critical path validation. This is the core evidence of completion. It’s not enough to just write it; it must run.
- Layer 3: System-Level Confirmation. End-to-end testing, integration validation, user scenario simulation. The final line of defense against premature declarations. It’s not enough to run; it must run correctly.
#3. Design Good “Red Pen Markups” for Agents
OpenAI introduced a particularly effective pattern during their Codex practice: error messages for agents should include fix instructions. Don’t just draw a big red cross like a lazy grader; be like a good teacher and write “here’s how you should change this” in the margins. Don’t use "Test failed", but use "Test failed: POST /api/reset-password returned 500. Check that the email service config exists in environment variables. The template file should be at templates/reset-email.html." This specific, actionable feedback allows the agent to self-correct without human intervention.
#4. Capture Runtime Signals
Effective runtime signals include:
- Did the application successfully start and reach a ready state?
- Did the critical feature paths execute successfully at runtime?
- Were database writes, file operations, and other side effects correct?
- Were temporary resources cleaned up?
#Key Takeaways
- Agents are systematically overconfident—confidence calibration bias is an objective reality. Filling out the exam paper doesn’t mean you got it right.
- Completion judgment must be externalized—the harness verifies independently; don’t trust the agent’s “feelings”. Students cannot grade their own exams.
- All three layers of validation are essential—syntax passing, behavior passing, system passing, progressing layer by layer.
- Error messages should be like a good teacher’s red pen markup—include specific fix steps so the agent can self-correct.
- No refactoring until core functionality is verified—the completion priority constraint is the key to preventing premature optimization.
#Only End-to-End Testing is True Verification
#The Blind Spots of Unit Testing
The design philosophy of unit testing is isolation—mocking dependencies and focusing solely on the unit under test. This philosophy makes unit testing fast and precise, but it also creates systematic blind spots. It’s like having each voice part practice with headphones on during a choir rehearsal—it sounds fine to them, but the issues only emerge when they come together:
Interface Mismatch: The file path passed by the render process to the preload script is a relative path, but the preload script expects an absolute path. Their respective unit tests both used mocks and passed. The issue is only discovered when the end-to-end flow is executed—just like two voice parts practicing independently and feeling fine, only to realize during the ensemble that one is singing in 4/4 time and the other in 3/4 time.
State Propagation Errors: A database migration changes the table schema, but the ORM caching layer still holds cache entries for the old schema. Unit tests provide a completely new mock environment every time, which won’t expose this cross-layer state inconsistency. It’s like changing the lyrics of a song, but someone is still singing the old version.
Resource Lifecycle Issues: The acquisition and release of file handles, database connections, and network sockets span multiple components. Unit tests create and destroy independent resources for each test, failing to expose resource contention or leaks. It’s like each voice part taking turns using the microphones during rehearsal, but when everyone goes on stage together, there aren’t enough mics.
Environment Dependency: The code behaves correctly in the test environment (where everything is mocked) but fails in the real environment due to configuration differences, network latency, or service unavailability. Like singing perfectly in the rehearsal room, but encountering audio feedback and wind interference at an outdoor festival.
#End-to-End Testing Not Only Changes Results, It Changes Behavior
This is something many people fail to realize: when an agent knows its work will be subjected to end-to-end testing, its coding behavior changes.
- Considering Component Interactions: While writing code, it will think about “how this interface connects with upstream,” rather than just focusing on a single function. Just like knowing you’ll eventually sing together, you’ll pay attention to other voice parts during practice.
- Respecting Architectural Boundaries: In systems with architectural constraints, end-to-end testing forces the agent to adhere to boundary rules. Like sheet music marked with “crescendo here,” you have to follow it.
- Handling Error Paths: End-to-end tests usually include failure scenarios, forcing the agent to consider exception handling. It’s like simulating “what if the mic suddenly dies” during rehearsal, so you know what to do.
#Testing Pyramid and Review Feedback Promotion


In Codex engineering practices, OpenAI emphasizes: error messages written for agents must include fix instructions. Don’t just write "Direct filesystem access in renderer"; write "Direct filesystem access in renderer. All file operations must go through the preload bridge. Move this call to preload/file-ops.ts and invoke it via window.api." This turns architectural rules into an auto-correction loop. Like a choir conductor who doesn’t just say “you sang that wrong,” but instead says “you were half a beat fast here, listen to the altos’ rhythm, and come in at measure 32.”
#Core Concepts
- Component Boundary Defects: Component A and B both pass their unit tests, but their interaction produces incorrect behavior. This is the type of issue end-to-end testing is best at catching—like choir parts that are individually correct but out of tune together.
- Testing Adequacy Gradient: Defects caught by unit tests <= defects caught by integration tests <= defects caught by end-to-end tests. Each layer up increases detection capability.
- Architectural Boundary Enforcement Rules: Turning rules from architecture documents (like “render process cannot access the file system directly”) into executable, automated checks. From “written on paper” to “running in CI.”
- Review Feedback Promotion: Converting repeated code review comments into automated tests. Every time a recurring issue is found, add a rule, and the harness automatically grows stronger. Like a conductor turning common rehearsal mistakes into warm-up exercises—the next time the same mistake is made, the exercise itself exposes it without the conductor needing to say a word.
- Agent-Oriented Error Messages: Failure messages shouldn’t just state “what went wrong,” but also tell the agent exactly how to fix it. This turns test failures into self-correcting feedback loops.
#How to Do It
#0. Define Architectural Boundaries First, Then Write E2E Tests
The prerequisite for end-to-end testing is clear system boundaries. If the architecture is a plate of spaghetti, end-to-end testing will only prove “this plate of spaghetti runs,” it won’t tell you where design intents were violated. It’s like a choir that hasn’t even divided into voice parts—no amount of rehearsal will make it sound good.
OpenAI’s experience: for codebases generated by agents, architectural constraints must be early prerequisites established on day one, not something to consider when the team grows larger. The reason is simple—agents will copy existing patterns in the repository, even if those patterns are uneven or suboptimal. Without architectural constraints, the agent will introduce more deviations in every session.
OpenAI adopted a “Layered Domain Architecture”—each business domain is divided into fixed layers: Types → Config → Repo → Service → Runtime → UI. Dependencies flow strictly forward, and cross-domain concerns enter through explicit Providers interfaces. Any other dependencies are forbidden and mechanically enforced via custom linting.
Key principle: Enforce invariants, don’t micromanage implementation. For example, require “data is parsed at the boundary,” but don’t dictate which library to use. Error messages must include fix instructions—not just saying “violation,” but telling the agent exactly how to change it.
Source: OpenAI: Harness engineering: leveraging Codex in an agent-first world
#1. Harness Must Include an End-to-End Layer
Make it explicit in your validation flow: for tasks involving cross-component changes, passing end-to-end tests is a prerequisite for completion:
1 | ## Validation Hierarchy |
#2. Turn Architectural Rules into Executable Checks
Every architectural constraint should have a corresponding test or lint rule:
1 | # Check if the render process directly calls Node.js APIs |
#3. Design Agent-Oriented Error Messages
Failure messages should contain three elements: what went wrong, why, and how to fix it:
1 | ERROR: Found direct import of 'fs' in src/renderer/App.tsx:12 |
#4. Establish a Review Feedback Promotion Process
Every time a new type of agent error is found during code review, turn it into an automated check. A month later, your harness will be significantly stronger than at the start of the month. It’s like rehearsal notes for a choir—recording issues found in every rehearsal so they can be checked before the next one. Over time, common errors decrease, and the music becomes more harmonious.
#Key Takeaways
- Unit tests are systematically blind to component boundary defects—their isolation design is exactly what prevents them from detecting interaction issues. Everyone singing correctly doesn’t mean the choir isn’t out of tune.
- End-to-end testing not only detects defects, it changes agent coding behavior—making it focus more on integration and boundaries.
- Architectural rules must be executable—not written in a document waiting to be read, but automatically checked on every commit.
- Error messages must be designed for agents—including specific steps on “how to fix it” to form a self-correcting loop.
- Review feedback promotion makes the harness automatically stronger—every category of captured defect becomes a permanent line of defense.
#Make the Agent’s Runtime Observable
#Core Concepts
- Runtime observability: System-level signals — logs, traces, process events, health checks. Answers “what did the system do.”
- Process observability: Visibility into harness decision artifacts — plans, scoring rubrics, acceptance criteria. Answers “why should this change be accepted.”
- Task trace: A complete decision-path record from task start to completion, analogous to request tracing in distributed systems. Every step the agent takes, with context, is recorded.
- Sprint contract: A short-term agreement negotiated before coding begins — specifying task scope, verification standards, and exclusions. The core tool for process observability.
- Evaluator rubric: Transforms quality evaluation from subjective judgment into evidence-based structured scoring. Makes different evaluators produce similar results for the same output.
- Layered observability: System-layer and process-layer observability designed simultaneously and reinforcing each other. Runtime signals explain behavior; process artifacts explain intent.
#Layered Observability

#Why This Happens
#The Real Cost of Missing Observability
When a harness lacks observability, four types of problems systematically appear:
Cannot distinguish “correct” from “looks correct”: A function looks perfectly right during code review — correct syntax, sound logic. But at runtime, an edge case handling error produces incorrect results under specific inputs. Only runtime traces can reveal that the actual execution path deviated from expectations.
Evaluation becomes mysticism: Without scoring rubrics and acceptance criteria, evaluators (human or agent) rely on implicit assumptions. The same output might get wildly different evaluations from different assessors. Quality assessment becomes non-reproducible.
Retries become blind guesses: When the agent doesn’t know why something failed, retry direction is random. It might try repeatedly in the wrong direction — fixing unrelated code paths while ignoring the actual failure root cause. Every blind retry costs tokens and time.
Session handoff information cliff: When incomplete work is handed to the next session, missing observability means the new session must diagnose system state from scratch. Anthropic’s long-running agent observations show this redundant diagnosis can consume 30-50% of total session time.
#A Real Claude Code Scenario
Imagine a harness using a “planner-generator-evaluator” three-role workflow, executing an “add dark mode to the app” task.
Without observability: The planner outputs a vague description. The generator implements dark mode based on that vagueness, but it doesn’t match the planner’s implicit expectations. The evaluator rejects based on their own implicit standards but can’t articulate what’s specifically wrong. The generator retries blindly based on vague rejection reasons. The cycle repeats 3-4 times, taking about 45 minutes, producing a barely acceptable output.
With full observability: The planner outputs a sprint contract — listing which components to modify, verification standards for each, and exclusions (no print styles). The generator implements according to the contract. Runtime observability records each component’s style loading and application process. The evaluator uses a scoring rubric to evaluate dimension by dimension, with specific evidence citations. One iteration produces a high-quality result, in about 15 minutes.
3x efficiency difference. The only change is observability.
#Why Agents Can’t Solve This Themselves
You might be thinking: “Can’t the agent just print its own logs?” The problems are:
- The agent doesn’t know what it doesn’t know — it won’t proactively record signals it doesn’t realize it needs.
- Log formats are inconsistent — different sessions use different log formats, making systematic analysis impossible.
- Process observability can’t be solved by logs — sprint contracts and scoring rubrics are structured artifacts that need harness-level support.
#How to Do It Right
#1. Build Runtime Signal Collection into the Harness
Don’t rely on the agent to print its own logs. The harness should automatically collect these signals:
- Application lifecycle: Startup, ready, running, shutdown phase states
- Feature path execution: Records of critical path execution, including entry points, checkpoints, and exits
- Data flow: Records of data flowing between components
- Resource utilization: Abnormal resource usage patterns (e.g., continuously growing memory)
- Errors and exceptions: Full error context, not just error messages
#2. Implement Sprint Contracts
Before each task starts, the generator and evaluator (which may be different invocations of the same agent) negotiate a contract:
1 | # Sprint Contract: Dark Mode Support |
#3. Establish an Evaluator Rubric
Turn “is it good or not” into quantifiable scoring:
1 | # Scoring Rubric |
#4. Standardize with OpenTelemetry
Create a trace for each harness session, a span for each task, and sub-spans for each verification step. Use standard attributes to annotate key information. This way observability data integrates with standard toolchains (Jaeger, Zipkin).
#Key Takeaways
- Observability is a harness architecture property — not a feature added after the fact, but a core capability that must be considered during design.
- Both observability layers are essential — runtime signals explain “what happened,” process artifacts explain “why it was done this way.”
- Sprint contracts front-load alignment — preventing “the generator built something the evaluator immediately rejects for foreseeable reasons.”
- Scoring rubrics make evaluation reproducible — different evaluators produce similar scores for the same output.
- Missing observability wastes 30-50% of session time on redundant diagnosis.
#Clean Handoff at the End of Every Session
#Core Concepts
- Clean state: The system satisfies five conditions at session end — build passes, tests pass, progress recorded, no stale artifacts, startup path available. Missing any one means the session isn’t “done.”
- Session integrity: Analogous to database transactions — either fully commit and leave a clean state, or roll back to the last consistent state. No middle ground.
- Quality document: An active artifact that continuously records quality ratings for each module. Not a one-time assessment, but a tracker showing whether the codebase is getting stronger or weaker over time.
- Cleanup loop: A regular maintenance session aimed at systematically reducing entropy in the codebase. Not an emergency fix, but routine operations.
- Harness simplification: As model capabilities improve, periodically remove harness components that are no longer necessary. A constraint essential today may be unnecessary overhead in three months.
- Idempotent cleanup: Cleanup operations produce the same result regardless of how many times they run. Ensures cleanup remains safe even in failure-retry scenarios.
#Five Dimensions of Clean State
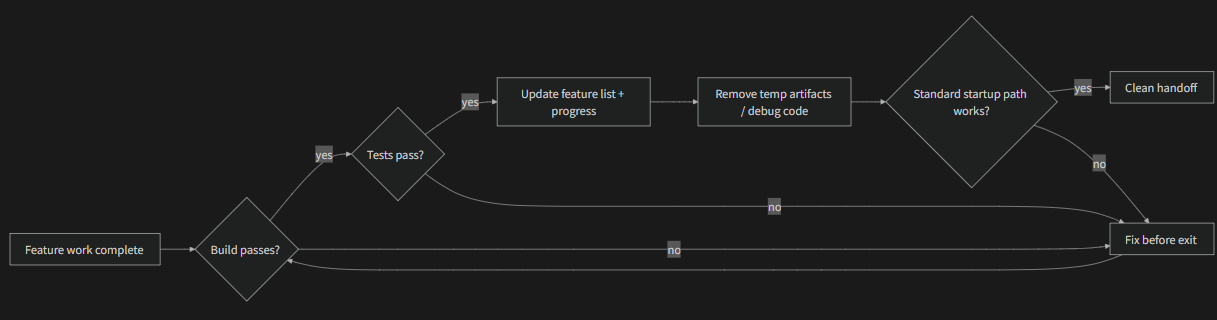
#Why This Happens
#Entropy Growth Is the Default State
Lehman’s laws of software evolution tell us: systems undergoing continuous change will inevitably increase in complexity unless actively managed. This is especially true for AI coding agents — every session introduces changes, and without cleanup at exit, technical debt accumulates exponentially.
Real data is telling. A project developed with agents for 12 weeks, without cleanup strategy:
- Week 1: Build pass rate 100%, test pass rate 100%, new session startup 5 min
- Week 4: Build 95%, tests 92%, startup 15 min
- Week 8: Build 82%, tests 78%, startup 35 min
- Week 12: Build 68%, tests 61%, startup 60+ min
Same project with a cleanup strategy:
- Week 1: 100%, 100%, 5 min
- Week 12: 97%, 95%, 9 min
After 12 weeks: build pass rate differs by 29 percentage points, new session startup time differs by 85%. This is not theoretical — it’s an observed difference.
#Five Dimensions of Clean State
Clean state isn’t just “the code compiles.” It’s five dimensions evaluated together:
Build dimension: Does the code build without errors? This is the most basic — the next session shouldn’t have to fix build errors first.
Test dimension: Do all tests pass? Including tests that existed before the session — the session is responsible for not breaking existing functionality. And it should be verified in CI, not just “works on my machine.”
Progress dimension: Is current progress recorded in a machine-readable artifact? Completed subtasks with their passing criteria, in-progress but incomplete subtasks with current state, not-yet-started subtasks. Good progress records reduce 60-80% of session startup diagnostic time.
Artifact dimension: Are there stale or ambiguous temporary artifacts? Debug logs, temporary files, commented-out code, TODO markers — all of these increase cognitive load for the next session.
Startup dimension: Is the standard startup path available? Can the next session start working without manual intervention? Environment initialization, codebase loading, context acquisition, task selection — these paths must not be broken.
#“Clean Up Later” Means Never Clean Up
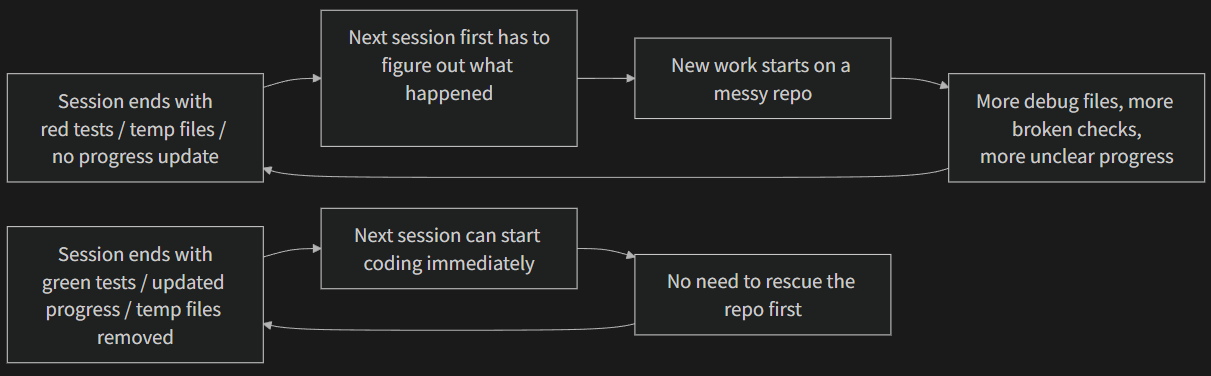
The most common mental trap is “no time to clean up this session, I’ll do it next time.” But the next agent session doesn’t know what you left behind — it sees a mess of code and uncertain state. It’ll spend significant time inferring “which parts of this code are intentional and which are temporary.”
Worse, every session has its own task objectives. The new session is there to do new work, not clean up the previous session’s mess. It’ll ignore the chaos and start new work on top of it, introducing more chaos on top of chaos. This is entropy’s positive feedback loop.
#How to Do It Right
#1. Clean State as a Completion Requirement
Define explicitly in the harness: session completion = task passes verification AND clean state check passes. Missing either one means the session isn’t complete. Write in CLAUDE.md:
1 | ## Session Exit Checklist |
#2. Dual-Mode Cleanup Strategy
Combine two cleanup modes:
Immediate cleanup (at end of every session): Clean up temporary artifacts created during the session, update feature list state, ensure build and tests pass. This is “reference counting” cleanup.
Periodic cleanup (weekly): Full-system scan — handle accumulated structural issues, update quality documents, run benchmark tests to detect drift. This is “tracing” cleanup.
#3. Maintain a Quality Document
A quality document is an active artifact that continuously scores each module:
1 | # Quality Document |
New sessions read this document and immediately know where to prioritize. Fix the lowest-scoring module first.
#4. Periodically Simplify the Harness
An important insight from Anthropic: every harness component exists because the model can’t reliably do something on its own. But as models improve, these assumptions become outdated. A constraint essential three months ago may be unnecessary overhead today.
Recommended practice: Every month, pick one harness component, temporarily disable it, and run benchmark tasks. If results don’t degrade, remove it permanently. If they do, restore it or replace with a lighter alternative.
#5. Cleanup Operations Must Be Idempotent
Cleanup scripts should be safe to run repeatedly:
1 | # Idempotent cleanup operations |
#Real-World Case
An Electron app developed with agents over 12 weeks, comparing two approaches:
Without cleanup strategy (control group): Week 12, build pass rate 68%, test pass rate 61%, new session startup 60+ min, stale artifacts 103.
With cleanup strategy (experimental group): Full clean-state check at every session end + weekly cleanup loop. Week 12, build pass rate 97%, test pass rate 95%, new session startup 9 min, stale artifacts 11.
By week 12, the experimental group’s build pass rate is 29 percentage points higher, test pass rate 34 points higher, and new session startup time 85% lower.
#Key Takeaways
- Clean state is a necessary condition for session completion — not optional housekeeping, but part of the “definition of done.”
- All five dimensions are required — build, tests, progress, artifacts, startup — each must be explicitly checked.
- Quality documents make codebase health trackable — you can only fix what you know is degrading.
- Periodically simplify the harness — as model capabilities improve, remove constraints that are no longer needed.
- “Clean up later” equals never cleaning up — entropy growth is the default; only active cleanup counteracts it.
#Clean Handoff at the End of Every Session
#Core Concepts
- Clean state: The system satisfies five conditions at session end — build passes, tests pass, progress recorded, no stale artifacts, startup path available. Missing any one means the session isn’t “done.”
- Session integrity: Analogous to database transactions — either fully commit and leave a clean state, or roll back to the last consistent state. No middle ground.
- Quality document: An active artifact that continuously records quality ratings for each module. Not a one-time assessment, but a tracker showing whether the codebase is getting stronger or weaker over time.
- Cleanup loop: A regular maintenance session aimed at systematically reducing entropy in the codebase. Not an emergency fix, but routine operations.
- Harness simplification: As model capabilities improve, periodically remove harness components that are no longer necessary. A constraint essential today may be unnecessary overhead in three months.
- Idempotent cleanup: Cleanup operations produce the same result regardless of how many times they run. Ensures cleanup remains safe even in failure-retry scenarios.
#Five Dimensions of Clean State
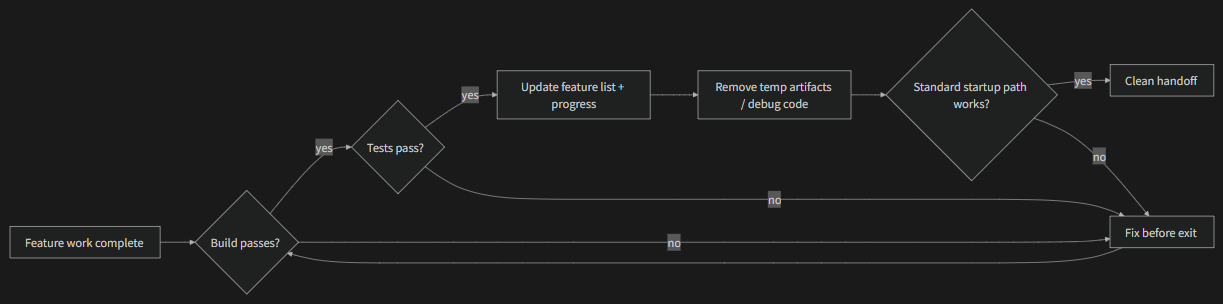
#Why This Happens
#Entropy Growth Is the Default State
Lehman’s laws of software evolution tell us: systems undergoing continuous change will inevitably increase in complexity unless actively managed. This is especially true for AI coding agents — every session introduces changes, and without cleanup at exit, technical debt accumulates exponentially.
Real data is telling. A project developed with agents for 12 weeks, without cleanup strategy:
- Week 1: Build pass rate 100%, test pass rate 100%, new session startup 5 min
- Week 4: Build 95%, tests 92%, startup 15 min
- Week 8: Build 82%, tests 78%, startup 35 min
- Week 12: Build 68%, tests 61%, startup 60+ min
Same project with a cleanup strategy:
- Week 1: 100%, 100%, 5 min
- Week 12: 97%, 95%, 9 min
After 12 weeks: build pass rate differs by 29 percentage points, new session startup time differs by 85%. This is not theoretical — it’s an observed difference.
#Five Dimensions of Clean State
Clean state isn’t just “the code compiles.” It’s five dimensions evaluated together:
Build dimension: Does the code build without errors? This is the most basic — the next session shouldn’t have to fix build errors first.
Test dimension: Do all tests pass? Including tests that existed before the session — the session is responsible for not breaking existing functionality. And it should be verified in CI, not just “works on my machine.”
Progress dimension: Is current progress recorded in a machine-readable artifact? Completed subtasks with their passing criteria, in-progress but incomplete subtasks with current state, not-yet-started subtasks. Good progress records reduce 60-80% of session startup diagnostic time.
Artifact dimension: Are there stale or ambiguous temporary artifacts? Debug logs, temporary files, commented-out code, TODO markers — all of these increase cognitive load for the next session.
Startup dimension: Is the standard startup path available? Can the next session start working without manual intervention? Environment initialization, codebase loading, context acquisition, task selection — these paths must not be broken.
#“Clean Up Later” Means Never Clean Up
The most common mental trap is “no time to clean up this session, I’ll do it next time.” But the next agent session doesn’t know what you left behind — it sees a mess of code and uncertain state. It’ll spend significant time inferring “which parts of this code are intentional and which are temporary.”
Worse, every session has its own task objectives. The new session is there to do new work, not clean up the previous session’s mess. It’ll ignore the chaos and start new work on top of it, introducing more chaos on top of chaos. This is entropy’s positive feedback loop.
#How to Do It Right
#1. Clean State as a Completion Requirement
Define explicitly in the harness: session completion = task passes verification AND clean state check passes. Missing either one means the session isn’t complete. Write in CLAUDE.md:
1 | ## Session Exit Checklist |
#2. Dual-Mode Cleanup Strategy
Combine two cleanup modes:
Immediate cleanup (at end of every session): Clean up temporary artifacts created during the session, update feature list state, ensure build and tests pass. This is “reference counting” cleanup.
Periodic cleanup (weekly): Full-system scan — handle accumulated structural issues, update quality documents, run benchmark tests to detect drift. This is “tracing” cleanup.
#3. Maintain a Quality Document
A quality document is an active artifact that continuously scores each module:
1 | # Quality Document |
New sessions read this document and immediately know where to prioritize. Fix the lowest-scoring module first.
#4. Periodically Simplify the Harness
An important insight from Anthropic: every harness component exists because the model can’t reliably do something on its own. But as models improve, these assumptions become outdated. A constraint essential three months ago may be unnecessary overhead today.
Recommended practice: Every month, pick one harness component, temporarily disable it, and run benchmark tasks. If results don’t degrade, remove it permanently. If they do, restore it or replace with a lighter alternative.
#5. Cleanup Operations Must Be Idempotent
Cleanup scripts should be safe to run repeatedly:
1 | # Idempotent cleanup operations |
#Key Takeaways
- Clean state is a necessary condition for session completion — not optional housekeeping, but part of the “definition of done.”
- All five dimensions are required — build, tests, progress, artifacts, startup — each must be explicitly checked.
- Quality documents make codebase health trackable — you can only fix what you know is degrading.
- Periodically simplify the harness — as model capabilities improve, remove constraints that are no longer needed.
- “Clean up later” equals never cleaning up — entropy growth is the default; only active cleanup counteracts it.
#Reference
https://github.com/walkinglabs/learn-harness-engineering
https://walkinglabs.github.io/learn-harness-engineering/en/